



Troubleshooting Process
Summary
This topic compare troubleshooting methods that use a systematic, layered approach. Start learning CCNA 200-301 for free right now!!
Table of Contents
General Troubleshooting Procedures
Troubleshooting can be time consuming because networks differ, problems differ, and troubleshooting experience varies. However, experienced administrators know that using a structured troubleshooting method will shorten overall troubleshooting time.
Therefore, the troubleshooting process should be guided by structured methods. This requires well defined and documented troubleshooting procedures to minimize wasted time associated with erratic hit-and-miss troubleshooting. However, these methods are not static. The troubleshooting steps taken to solve a problem are not always the same or executed in the exact same order.
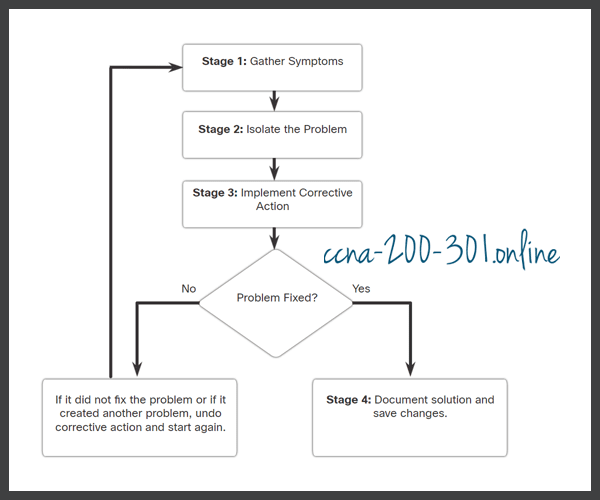
There are several troubleshooting processes that can be used to solve a problem. The figure displays the logic flowchart of a simplified three-stage troubleshooting process. However, a more detailed process may be more helpful to solve a network problem.
Seven-Step Troubleshooting Process
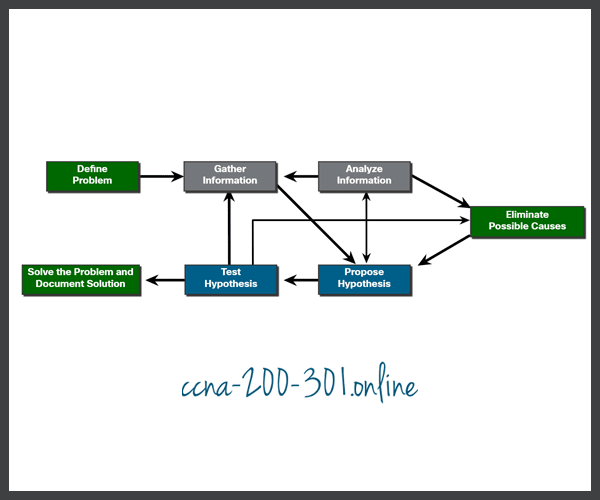
The figure displays a more detailed seven-step troubleshooting process. Notice how some steps interconnect. This is because, some technicians may be able to jump between steps based on their level of experience.
Question End Users
Many network problems are initially reported by an end user. However, the information provided is often vague or misleading. For example, users often report problems such as “the network is down”, “I cannot access my email”, or “my computer is slow”.
In most cases, additional information is required to fully understand a problem. This usually involves interacting with the affected user to discover the “who”, “what”, and “when” of the problem.
The following recommendations should be employed when communicate with user:
- Speak at a technical level they can understand and avoid using complex terminology.
- Always listen or read carefully what the user is saying. Taking notes can be helpful when documenting a complex problem.
- Always be considerate and empathize with users while letting them know you will help them solve their problem. Users reporting a problem may be under stress and anxious to resolve the problem as quickly as possible.
When interviewing the user, guide the conversation and use effective questioning techniques to quickly ascertain the problem. For instance, use open questions (i.e., requires detailed response) and closed questions (i.e., yes, no, or single word answers) to discover important facts about the network problem.
The table provides some questioning guidelines and sample open ended end-user questions.
When done interviewing the user, repeat your understanding of the problem to the user to ensure that you both agree on the problem being reported.
| Guidelines | Example Open Ended End-User Questions |
|---|---|
| Ask pertinent questions. |
|
| Determine the scope of the problem. |
|
| Determine when the problem occurred / occurs. |
|
| Determine if the problem is constant or intermittent. |
|
| Determine if anything has changed. | What has changed since the last time it did work? |
| Use questions to eliminate or discover possible problems. |
|
Gather Information
To gather symptoms from suspected networking device, use Cisco IOS commands and other tools such as packet captures and device logs.
The table describes common Cisco IOS commands used to gather the symptoms of a network problem.
| Command | Description |
|---|---|
ping {host | ip-address} |
|
traceroute destination |
|
telnet {host | ip-address} |
|
ssh -l user-id ip-address |
|
show ip interface brief show ipv6 interface brief |
|
show ip route show ipv6 route | Displays the current IPv4 and IPv6 routing tables, which contains the routes to all known network destinations |
show protocols | Displays the configured protocols and shows the global and interface-specific status of any configured Layer 3 protocol |
debug | Displays a list of options for enabling or disabling debugging events |
Troubleshooting with Layered Models
The OSI and TCP/IP models can be applied to isolate network problems when troubleshooting. For example, if the symptoms suggest a physical connection problem, the network technician can focus on troubleshooting the circuit that operates at the physical layer.
The figure shows some common devices and the OSI layers that must be examined during the troubleshooting process for that device.
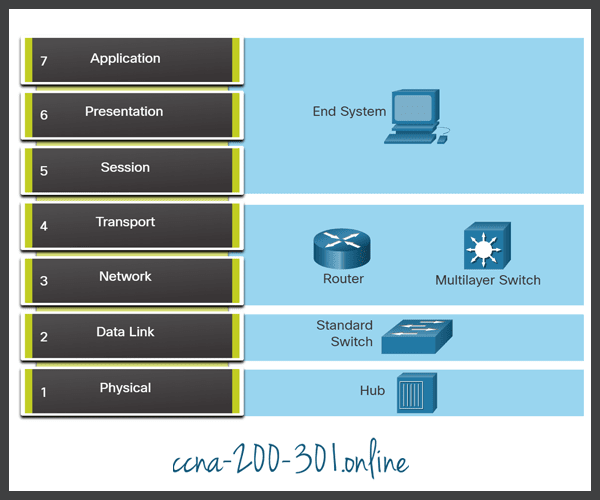
Notice that routers and multilayer switches are shown at Layer 4, the transport layer. Although routers and multilayer switches usually make forwarding decisions at Layer 3, ACLs on these devices can be used to make filtering decisions using Layer 4 information.
Structured Troubleshooting Methods
There are several structured troubleshooting approaches that can be used. Which one to use will depend on the situation. Each approach has its advantages and disadvantages. This topic describes methods and provides guidelines for choosing the best method for a specific situation.
In bottom-up troubleshooting, you start with the physical components of the network and move up through the layers of the OSI model until the cause of the problem is identified, as shown in the figure.
Bottom-up troubleshooting is a good approach to use when the problem is suspected to be a physical one. Most networking problems reside at the lower levels, so implementing the bottom-up approach is often effective.
The disadvantage with the bottom-up troubleshooting approach is it requires that you check every device and interface on the network until the possible cause of the problem is found. Remember that each conclusion and possibility must be documented so there can be a lot of paper work associated with this approach. A further challenge is to determine which devices to start examining first.

In the figure, top-down troubleshooting starts with the end-user applications and moves down through the layers of the OSI model until the cause of the problem has been identified.
End-user applications of an end system are tested before tackling the more specific networking pieces. Use this approach for simpler problems, or when you think the problem is with a piece of software.
The disadvantage with the top-down approach is it requires checking every network application until the possible cause of the problem is found. Each conclusion and possibility must be documented. The challenge is to determine which application to start examining first.

The figure shows the divide-and-conquer approach to troubleshooting a networking problem.
The network administrator selects a layer and tests in both directions from that layer.
In divide-and-conquer troubleshooting, you start by collecting user experiences of the problem, document the symptoms and then, using that information, make an informed guess as to which OSI layer to start your investigation. When a layer is verified to be functioning properly, it can be assumed that the layers below it are functioning. The administrator can work up the OSI layers. If an OSI layer is not functioning properly, the administrator can work down the OSI layer model.
For example, if users cannot access the web server, but they can ping the server, then the problem is above Layer 3. If pinging the server is unsuccessful, then the problem is likely at a lower OSI layer.

This is one of the most basic troubleshooting techniques. The approach first discovers the actual traffic path all the way from source to destination. The scope of troubleshooting is reduced to just the links and devices that are in the forwarding path. The objective is to eliminate the links and devices that are irrelevant to the troubleshooting task at hand. This approach usually complements one of the other approaches.
This approach is also called swap-the-component because you physically swap the problematic device with a known, working one. If the problem is fixed, then the problem is with the removed device. If the problem remains, then the cause may be elsewhere.
In specific situations, this can be an ideal method for quick problem resolution, such as with a critical single point of failure. For example, a border router goes down. It may be more beneficial to simply replace the device and restore service, rather than to troubleshoot the issue.
If the problem lies within multiple devices, it may not be possible to correctly isolate the problem.
This approach is also called the spot-the-differences approach and attempts to resolve the problem by changing the nonoperational elements to be consistent with the working ones. You compare configurations, software versions, hardware, or other device properties, links, or processes between working and nonworking situations and spot significant differences between them.
The weakness of this method is that it might lead to a working solution, without clearly revealing the root cause of the problem.
This approach is also called the shoot-from-the-hip troubleshooting approach. This is a less-structured troubleshooting method that uses an educated guess based on the symptoms of the problem. Success of this method varies based on your troubleshooting experience and ability. Seasoned technicians are more successful because they can rely on their extensive knowledge and experience to decisively isolate and solve network issues. With a less-experienced network administrator, this troubleshooting method may be more like random troubleshooting.
Guidelines for Selecting a Troubleshooting Method
To quickly resolve network problems, take the time to select the most effective network troubleshooting method.
The figure illustrates which method could be used when a certain type of problem is discovered.

For instance, software problems are often solved using a top-down approach while hardware-based problem are solved using the bottom-up approach. New problems may be solved by an experienced technician using the divide-and-conquer method. Otherwise, the bottom-up approach may be used.
Troubleshooting is a skill that is developed by doing it. Every network problem you identify and solve gets added to your skill set.
Ready to go! Keep visiting our networking course blog, give Like to our fanpage; and you will find more tools and concepts that will make you a networking professional.

